初始装载
在数据仓库可以使用前,需要装载历史数据。这些历史数据是导入进数据仓库的第一个数据集合。
首次装载被称为初始装载,一般是一次性工作。由最终用户来决定有多少历史数据进入数据仓库。例如,数据仓库使用的开始时间是2015年3月1日,而用户希望装载两年的历史数据,那么应该初始装载2013年3月1日到2015年2月28日之间的源数据。在2015年3月2日装载2015年3月1日的数据(假设执行频率是每天一次),之后周期性地每天装载前一天的数据。
在装载事实表前,必须先装载所有的维度表。因为事实表需要引用维度的代理键。这不仅针对初始装载,也针对定期装载。本次实验主要说明执行初始装载的步骤,包括标识源数据、维度历史的处理、使用HiveQL开发和验证初始装载过程。
标识源数据
设计开发初始装载步骤前需要识别数据仓库的每个事实表和每个维度表用到的并且是可用的源数据,还要了解数据源的特性,例如文件类型、记录结构和可访问性等。
下表显示的是销售订单示例数据仓库需要的源数据的关键信息,包括源数据表、对应的数据仓库目标表等属性。这类表格通常称作数据源对应图,因为它反映了每个从源数据到目标数据的对应关系。生成这个表格的过程就是逻辑数据映射。在本示例中,客户和产品的源数据直接与其数据仓库里的目标表customer_dim和product_dim表相对应,而销售订单事务表是多个数据仓库表的数据源。

纬度历史的数据
大多数维度值是随着时间改变的,如客户改变了姓名,产品的名称或分类变化等。当一个维度改变,比如当一个产品有了新的分类时,有必要记录维度的历史变化信息。在这种情况下,product_dim表里必须既存储产品老的分类,也存储产品当前的分类。并且,老的销售订单里的产品引用老的分类。
渐变维(SCD)即是一种在多维数据仓库中实现维度历史的技术。有三种不同的SCD技术:SCD类型1(SCD1),SCD类型2(SCD2),SCD类型3(SCD3)。
- SCD1:通过更新维度记录直接覆盖已存在的值,它不维护记录的历史。SCD1一般用于修改错误的数据。
- SCD2:在源数据发生变化时,给维度记录建立一个新的“版本”记录,从而维护维度历史。SCD2不删除、修改已存在的数据。
- SCD3:通常用作保持维度记录的几个版本。它通过给某个数据单元增加多个列来维护历史。例如,为了记录客户地址的变化,customer_dim维度表有一个customer_address列和一个previous_customer_address列,分别记录当前和上一个版本的地址。SCD3可以有效维护有限的历史,而不像SCD2那样保存全部历史。SCD3很少使用。它只适用于数据的存储空间不足并且用户接受有限维度历史的情况。
纬度历史的处理
同一维度表中的不同字段可以有不同的变化处理方式。在本示例中,客户维度历史的客户名称使用SCD1,客户地址使用SCD2,产品维度的两个属性,产品名称和产品类型都使用SCD2保存历史变化数据。
多维数据仓库中的维度表和事实表一般都需要有一个代理键,作为这些表的主键,代理键一般由单列的自增数字序列构成。Hive没有关系数据库中的自增列,但它也有一些对自增序列的支持,通常有两种方法生成代理键:使用row_number()窗口函数或者使用一个名为UDFRowSequence的用户自定义函数(UDF)。
- 假设有维度表
tbl_dim和过渡表tbl_stg,现在要将tbl_stg的数据装载到tbl_dim,装载的同时生成维度表的代理键。 - 用
row_number()函数生成代理键
先建立测试所需的维度表和事实表,并插入数据:
use test;
drop table if exists tbl_dim;
drop table if exists tbl_stg;
create table tbl_stg(id int, sk int, address varchar(10));
insert into tbl_stg values(2,2,'qwe');
insert into tbl_stg values(3,3,'asd');
insert into tbl_stg values(4,4,'zxc');
create table tbl_dim(key int, id int,sk int, address varchar(10));
用row_number()函数生成代理建
set hive.mapred.mode;
set hive.mapred.mode=nonstrict;
set hive.mapred.mode;
set hive.strict.checks.cartesian.product;
set hive.strict.checks.cartesian.product=false;
set hive.strict.checks.cartesian.product;
先查询维度表中已有记录最大的代理键值,如果维度表中还没有记录,利用coalesce函数返回0。然后使用cross join连接生成过渡表和最大代理键值的笛卡尔集,最后使用row_number()函数生成行号,并将行号与最大代理键值相加的值,作为新装载记录的代理键。
insert into tbl_dim select row_number() over (order by tbl_stg.id) + t2.sk_max, tbl_stg.* from tbl_stg cross join (select coalesce(max(sk),0) sk_max from tbl_dim) t2;
此时,维度表中已经装载了数据:

用UDFRowSequence生成代理键
hive-contrib-2.0.0.jar中包含一个生成记录序号的自定义函数udfrowsequence。上面的语句先加载JAR包,然后创建一个名为row_sequence()的临时函数作为调用UDF的接口,这样可以为查询的结果集生成一个自增伪列。之后就和row_number()写法类似了,只不过将窗口函数row_number()替换为row_sequence()函数。truncate table tbl_dim; add jar /usr/local/hive/lib/hive-contrib-2.3.0.jar; create temporary function row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'; insert into tbl_dim select row_sequence() + t2.sk_max, tbl_stg.* from tbl_stg cross join(select coalesce(max(sk),0) sk_max from tbl_dim)t2;结果与之前相同
初始数据抽取
建立sqoop导入作业,抽取sales_order数据到RDS库
use rds;
truncate table customer;
truncate table product;
truncate table sales_order;
##创建作业
sqoop job --delete myjob_incremental_import
sqoop job --create myjob_incremental_import \
-- import \
--connect "jdbc:mysql://localhost:3306/source?useSSL=false&user=root&password=scott5183" \
--table sales_order \
--columns "order_number, customer_number, product_code, order_date, entry_date, order_amount" \
--hive-import \
--hive-table rds.sales_order \
--incremental append \
--check-column order_amount \
--last-value 0
sqoop job --exec myjob_incremental_import
全量抽取客户和产品数据到RDS库
sqoop import --connect jdbc:mysql://localhost:3306/source?useSSL=false --username=root --password scott5183 --table customer --hive-import --hive-table rds.customer --hive-overwrite
sqoop import --connect jdbc:mysql://localhost:3306/source?useSSL=false --username=root --password scott5183 --table product --hive-import --hive-table rds.product --hive-overwrite
装载客户维度表
use dw;
truncate table customer_dim;
truncate table product_dim;
truncate table order_dim;
truncate table sales_order_fact;
insert into customer_dim
select row_number() over (order by t1.customer_number) + t2.sk_max, t1.customer_number, t1.customer_name, t1.customer_street_address,t1.customer_zip_code, t1.customer_city, t1.customer_state,1,'2016-03-01','2200-01-01'
from rds.customer t1 cross join(select coalesce(max (customer_sk),0) sk_max from customer_dim) t2;
装载产品维度表
insert into product_dim
select row_number() over (order by t1.product_code) + t2.sk_max, product_code, product_name, product_category,1, '2016-03-01','2200-01-01'
from rds.product t1 cross join(select coalesce(max (product_sk),0) sk_max from product_dim) t2;
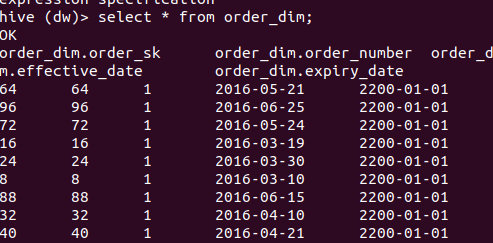
装载订单维度表
insert into order_dim
select row_number() over (order by t1.order_number) + t2.sk_max, order_number,1, order_date,'2200-01-01'
from rds.sales_order t1 cross join(select coalesce(max (order_sk),0) sk_max from order_dim) t2;
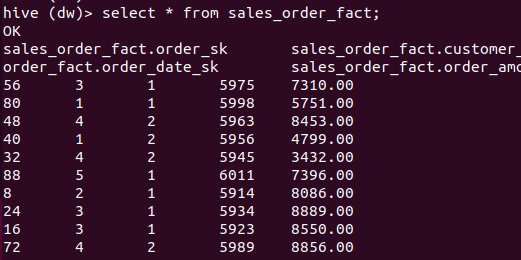
装载销售订单事实表
insert into sales_order_fact
select order_sk,customer_sk,product_sk,date_sk,order_amount
from rds.sales_order a,order_dim b, customer_dim c, product_dim d, date_dim e
where a.order_number = b.order_number and a.customer_number = c.customer_number and a.product_code = d.product_code and to_date(a.order_date) = e.`date`;
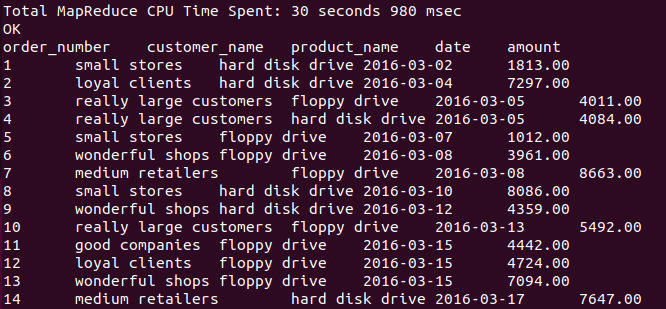
验证初始装载的正确性
use dw;
select * from customer_dim;
select * from product_dim;
select * from order_dim;
select * from sales_order_fact;
select * from date_dim;
select order_number, customer_name, product_name,`date`, order_amount amount from sales_order_fact a, customer_dim b,product_dim c ,order_dim d, date_dim e where a.customer_sk=b.customer_sk and a.product_sk = c.product_sk and a.order_sk = d.order_sk and a.order_date_sk = e.date_sk order by order_number;